Categorical Data and One Hot Encoding .
Categorical Data.
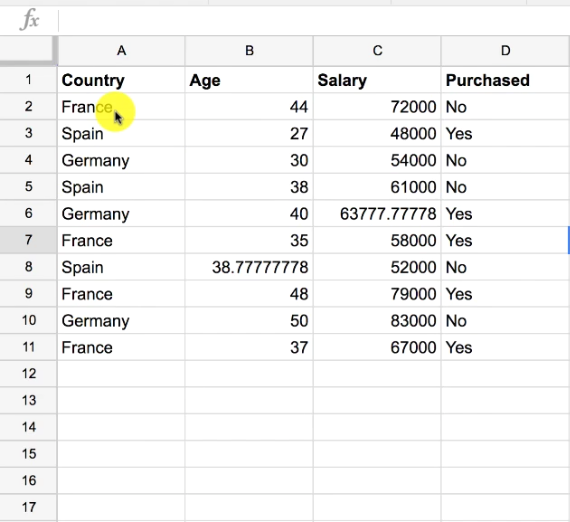
Consider the above data set,
In this dataset, we have two categorical variables.
First one is Country and the second one Purchased.
Reason For Encoding our categorical variables.
Since machine learning model is based on the mathematical equation, therefore we can’t keep text in our equation.And we want only numbers in an equation.
Therefore to use text in Machine learning equation we use label encoding .
from sklearn.preprocessing import LabelEncoder
labelEncoderX=LabelEncoder()
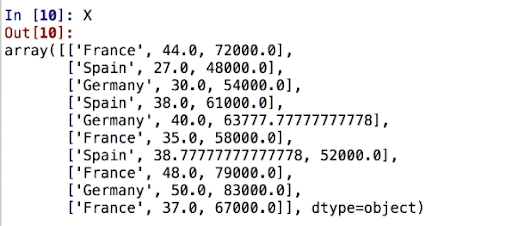
X[:,0]=labelEncoderX.fit_transform(X[:,0])Before Applying LabelEncoding To Our Data.
After Applying LabelEncoding To Our Data.
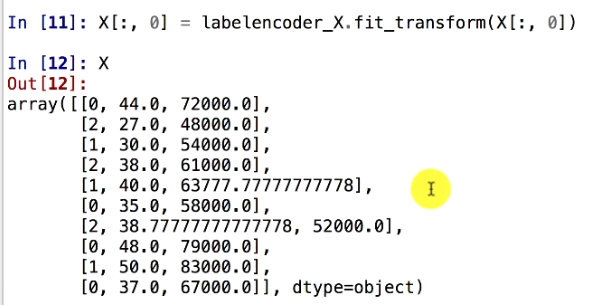
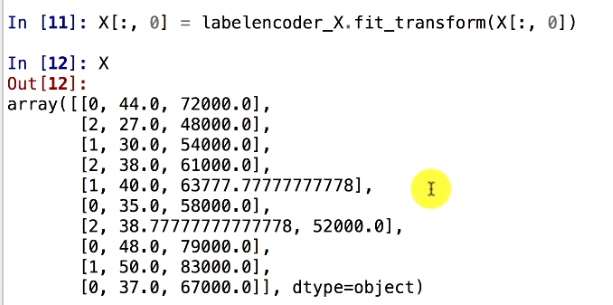
Here we can observe that the first column of the matrix containing the name of the countries is encoded into Numerical values.
France is encoded as 1.
Spain is encoded as 2.
And, Germany as 3.
Here due to label encoding our machine learning model will encounter some problem.
Since machine learning models are based on equations we have converted our text into numbers so that we can use it in our equations.
France is encoded as 1.
Spain is encoded as 2.
And, Germany as 3.
However 2 is greater than 1 and 3 is greater than 2 and 1, equations in the models think Spain has the higher value than France and Germany has higher value then Spain and France.But that’s not the case, these three are categories and there is no relational comparison between them.
Therefore we can’t compare France, Spain, and Germany. And say that Spain is greater than France. Germany is greater than Spain and France.
Consider another example where we have, Small Medium And Large.Then we can express the orders between these values as the Medium is greater than a Small. And Large is greater than Medium and Small.
Therefore we need to prevent our machine learning model from Having a relational comparison between this categorical values.
For this purpose, we use
DUMMY ENCODING.
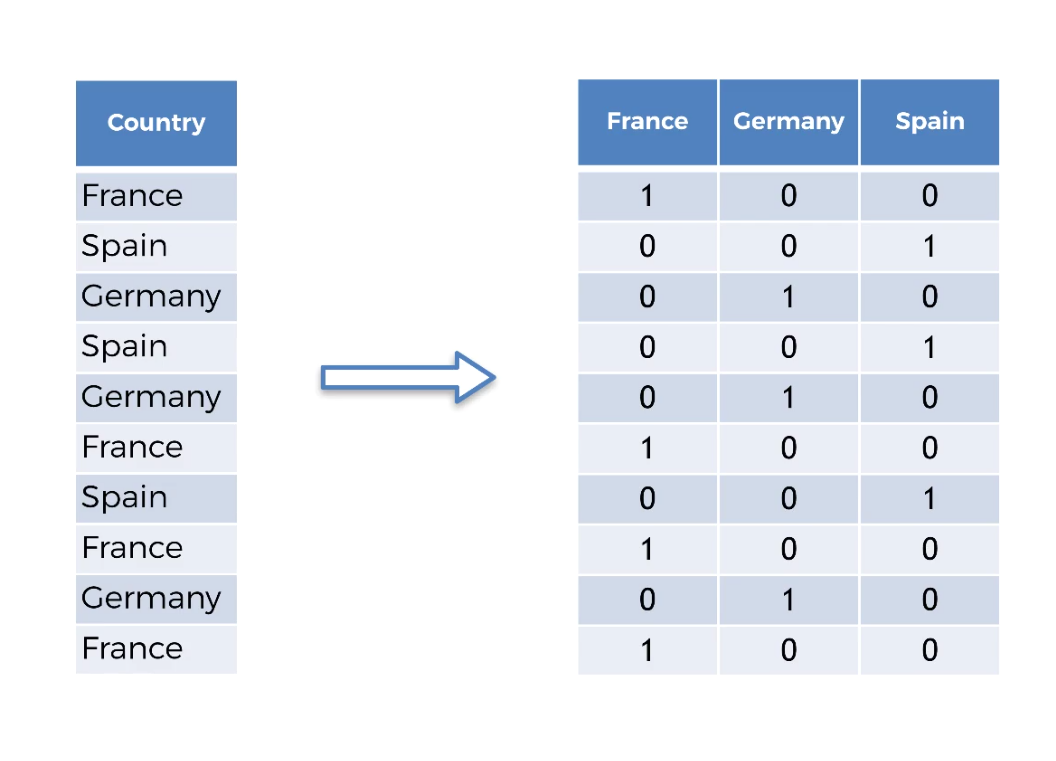
In Dummy Encoding, The number of columns is equals to the number of categories. Each of these columns will correspond to one country.
Note :In each column there will be either 0 or 1.
Say for example if the country is France there will be ‘1’ in the France Column.
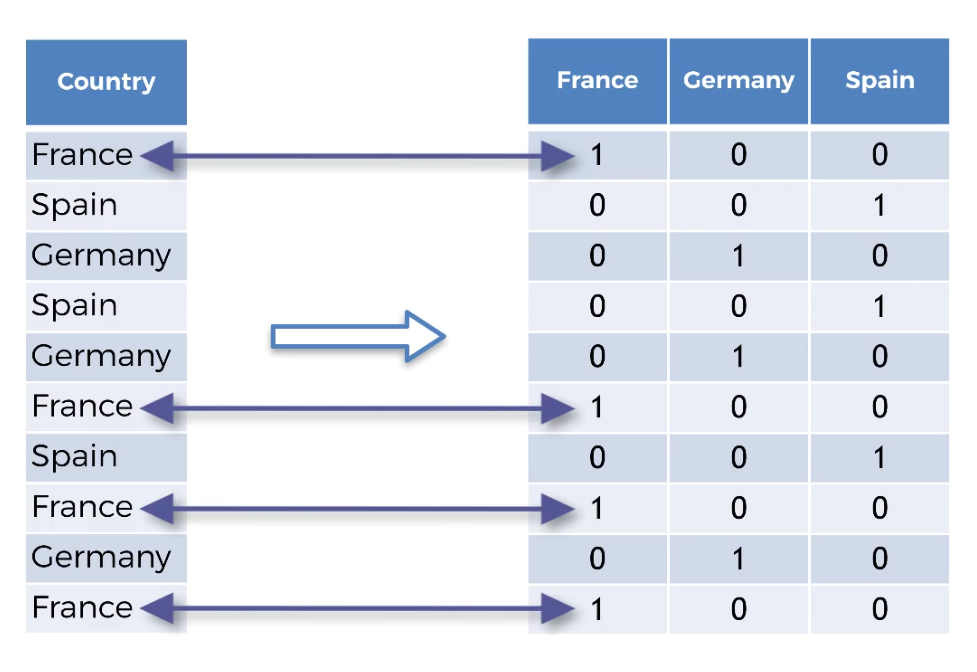
And ‘0’, If the country is not France.
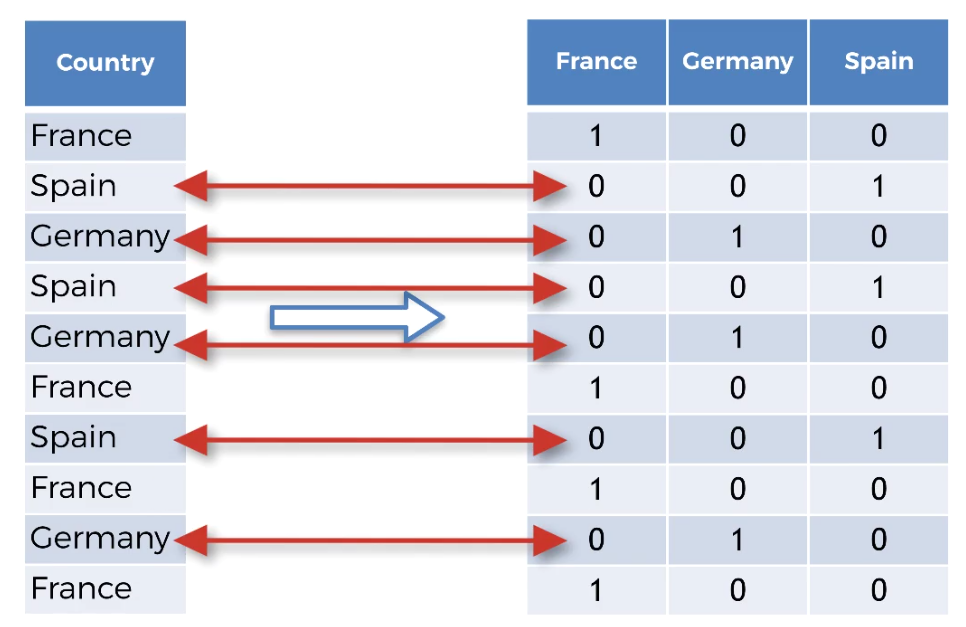
For this purpose, we use another class ie .OneHotEncoder class
Reason For OneHotEncoding.
We use one hot encoder to perform “binarization” of the category and include it as a feature to train the model.
Code To OneHotEncode Our Data.
from sklearn.preprocessing import OneHotEncoder
#Create the Object
oneHotEncode=OneHotEncoder()
#Fit the data to OneHotEncode object.
oneHotEncode =OneHotEncoder(categorical_features=[0])
X=oneHotEncode.fit_transform(X).toarray()
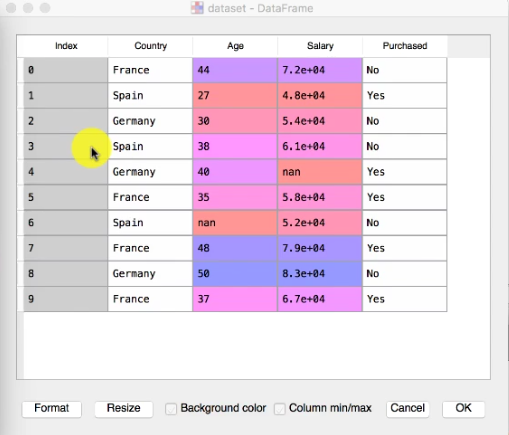
Dataset -
Before LabelEncoding and OneHotEncoding.
After LabelEncoding
After Both LabelEncoding and OneHotEncoding.
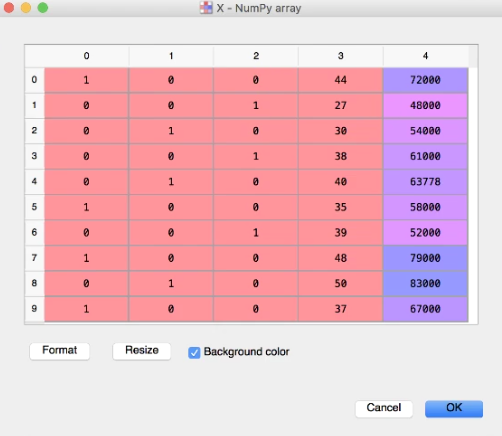
For the purchased column we won’t use OneHotEncoder as there is only Yes or No(Dependent Variable and there is no order between the two.
labelEncoderY=LabelEncoder()
Y=labelEncoderY.fit_transform(Y)
Complete Code:
from sklearn.preprocessing import LabelEncoder ,OneHotEncoder
labelEncoderX=LabelEncoder()
X[:,0]=labelEncoderX.fit_transform(X[:,0])
oneHotEncode=OneHotEncoder()
oneHotEncode =OneHotEncoder(categorical_features=[0])
X=oneHotEncode.fit_transform(X).toarray()